


 matt@aihealthician.co.uk
matt@aihealthician.co.uk




TL;DR:
- Personalised health analysis integrates individual data for targeted, meaningful interventions beyond population averages.
- Accurate data collection, cleaning, and validation are essential for effective health personalization.
- Human oversight and clinical validation remain critical for safe, effective, and trustworthy health optimization.
Most people accumulate stacks of health metrics — wearable readouts, blood panels, sleep scores — yet still feel stuck, tired, and unsure what to change. The gap between raw data and meaningful action is where performance stalls. Generic population guidelines, built on statistical averages, simply cannot account for your unique physiology, lifestyle pressures, or genetic tendencies. This article takes you through the full arc: understanding why personalisation matters, gathering and preparing your data properly, selecting the right analytical methods, and validating your results so that every intervention you make is grounded in your own biological reality.
Table of Contents
- Understanding your health data: why personalisation matters
- Collecting and preparing your health data
- Choosing and applying the right personalisation methods
- Testing, validating, and refining your personalised approach
- A fresh perspective: what most personalisation advice gets wrong
- Next steps: unlock your personalised health optimisation
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Personalisation trumps averages | Individualised data insights drive stronger health improvements than generic guidelines. |
| Data quality matters | Accurate, comprehensive tracking and preparation allow AI to deliver meaningful recommendations. |
| Validate with professionals | Combining AI personalisation with clinician review ensures safety and long-term effectiveness. |
| Privacy is essential | Local data storage and ownership protect your information and build lasting trust. |
Understanding your health data: why personalisation matters
Every major public health guideline, whether from the CDC or the WHO, is built on population averages. That means they reflect the midpoint of a bell curve that includes sedentary office workers, elite athletes, people with autoimmune conditions, and everything in between. If you sit outside that midpoint in any meaningful way, blanket recommendations will either underserve or actively mislead you.
The shift toward personalised health is not a trend. It is a logical response to the explosion of affordable biological data now available to individuals. Wearables track continuous heart rate variability, sleep architecture, and blood oxygen. At-home lab panels measure cortisol, thyroid hormones, inflammatory markers, and nutrient status. Continuous glucose monitors reveal how your metabolism responds to specific foods at specific times of day. Individually, these data streams are interesting. Combined and interpreted against your personal baseline, they become actionable.
“Population-based guidelines (CDC/WHO) rely on averages and miss individual variability. Machine learning can cluster individuals into more useful subgroups, but AI needs human oversight for ethics and safety to remain non-negotiable.”
This is precisely why N=1 strategies, protocols designed around a single individual’s data, consistently outperform generalised advice for high performers. The research supports this. When machine learning algorithms cluster people by biometric and demographic data rather than applying uniform thresholds, the resulting subgroups reveal meaningful physiological differences that population norms obscure entirely.
Key reasons personalised data outperforms generic advice:
- Your “normal” ranges for markers like ferritin, testosterone, or fasting glucose may sit at the edge of population reference ranges but still represent optimal function for you personally.
- Nutrient needs vary substantially based on genetics, gut microbiome composition, and activity load.
- Recovery capacity differs between individuals even with identical training volumes.
- Stress responses, sleep requirements, and hormonal rhythms are highly individual.
You can explore data-driven health examples that illustrate how this plays out in real performance contexts, and the benefits of health data tracking that make the case for investing in your own data infrastructure from the outset.
Human oversight remains critical throughout. AI can identify patterns in your data at a speed and resolution that no clinician could match manually. But interpreting those patterns safely, especially when medications, genomics, or comorbidities are involved, requires experienced clinical judgement. The two must work in tandem.
Collecting and preparing your health data
Before any algorithm or analysis can add value, you need clean, representative data. This sounds straightforward but is where most people stumble. Inconsistent measurement timing, device drift, and data gaps all introduce noise that corrupts downstream insights.
What to collect
| Data category | Examples | Collection method |
|---|---|---|
| Biometrics | Heart rate, HRV, blood pressure, SpO2 | Wearables, clinical devices |
| Blood biomarkers | Full blood count, hormones, metabolic panel | Lab testing, at-home kits |
| Genomics | SNPs, methylation patterns | DNA testing services |
| Daily logs | Sleep, nutrition, mood, stress | Apps, manual tracking |
| Device data | Steps, VO2 max estimates, body composition | Fitness trackers, DEXA scans |
| Medication and supplement logs | Dosages, timing, interactions | Manual records |
Each category adds a distinct layer of resolution. Biometrics tell you what your body is doing right now. Biomarkers reveal systemic function over weeks. Genomics inform long-term tendencies and drug or nutrient sensitivities. Together, they build a picture no single test can provide.
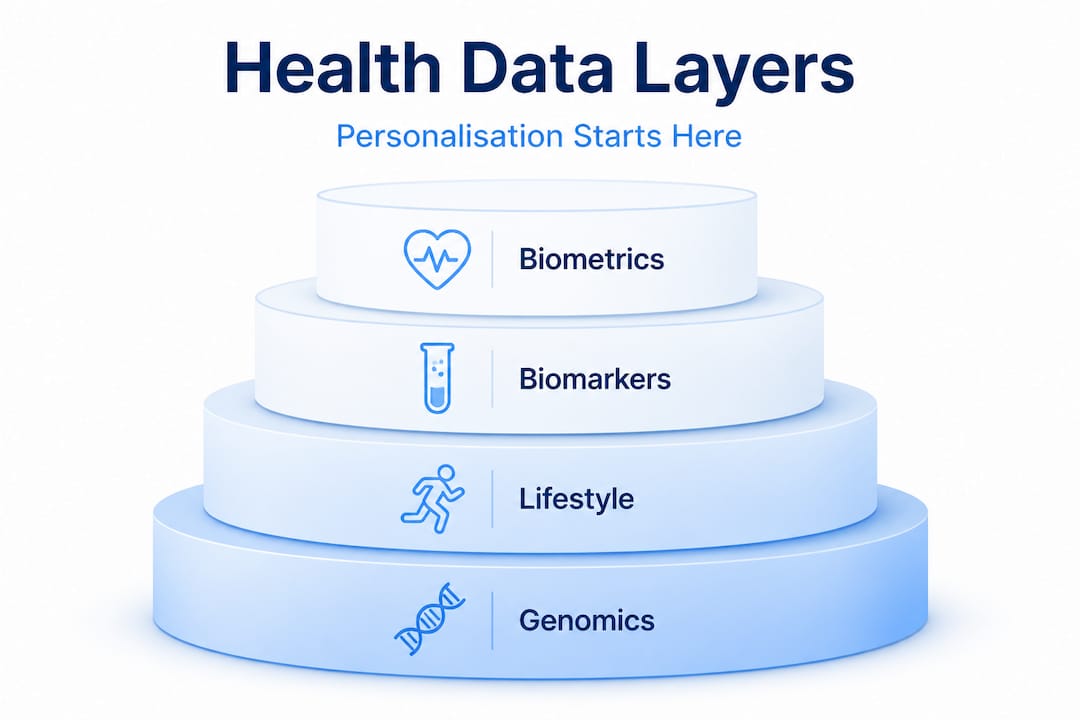
Handling common data problems
Real-world health data is messy. Data gaps, device inconsistencies, and medication or genomics interactions are edge cases that every serious practitioner encounters. Missing values from skipped measurements can be imputed using your own historical patterns rather than population means, which preserves individual specificity. Device inconsistencies, such as HRV variance between different wearables, should be normalised by establishing a calibration period where you wear both simultaneously. Bias is a subtler issue: many algorithms were trained on datasets that underrepresent certain ethnic groups, which can introduce systematic error in your outputs if you are not in the majority demographic.

Pro Tip: Run a 30-day data audit before starting any personalisation protocol. Identify which metrics have gaps greater than 10%, which devices show inconsistent readings, and whether your logging habits are genuinely sustainable. Clean data from 30 days beats noisy data from six months.
Privacy fundamentals
Sensitive biological data requires serious consideration about where it lives. Local storage keeps data on your own device, removing third-party access risk entirely. Federated learning allows AI models to train on your data without that data ever leaving your device. Cloud solutions offer convenience but introduce data ownership ambiguity and potential breach risk. For anything involving genomics or medication history, local or federated approaches are strongly preferable.
For a deeper look at how this works in practice, see biological data analysis examples and a broader guide to analysing health data effectively.
Choosing and applying the right personalisation methods
With clean data in hand, the next decision is which analytical method fits your goals. This is where many people either overcomplicate things or chase shiny AI tools without understanding their limitations.
Comparison of main personalisation methods
| Method | Best use case | Strengths | Limitations |
|---|---|---|---|
| K-means clustering | Grouping your data into distinct lifestyle or metabolic states | Fast, interpretable | Requires defined cluster number upfront |
| Regression models | Predicting outcomes from activity, nutrition, or sleep inputs | Strong predictive power | Assumes linear relationships |
| XGBoost | Personalised fitness and metabolic recommendations | High accuracy on biometric data, handles complex patterns | Computationally intensive |
| LLMs with RAG | Synthesising recommendations from your data and literature | Flexible, conversational | Limited in medical validation even with retrieval augmentation |
XGBoost, a gradient-boosted decision tree algorithm, achieves a mean Intersection over Union of 0.789 and a Dice coefficient of 0.841 for personalised fitness recommendations on NHANES data. These are strong benchmark scores that reflect its real-world effectiveness. Large language models (LLMs) with retrieval-augmented generation (RAG) can synthesise your personal data with published research in seconds, but they have meaningful limitations in formal medical validation, meaning they should inform rather than replace clinical decision-making.
How to start personalising
- Define your primary outcome. Energy, sleep quality, body composition, or cardiovascular resilience each require different data inputs and analytical approaches. Pick one primary metric to optimise first.
- Establish your baseline. Collect at least three to four weeks of consistent data before running any analysis. This gives algorithms enough signal to identify genuine patterns rather than noise.
- Select a method matched to your outcome. Use clustering to identify which lifestyle states correlate with your best and worst performance days. Use regression if you want to predict how a specific change (e.g., increasing protein intake) will affect a target outcome.
- Fine-tune on your own data. AI and ML models like clustering on biometrics and demographics, or LLMs with RAG for recommendations, reach their full potential when fine-tuned on individual data rather than relying solely on population-trained defaults.
- Validate with real-world outcomes. Run each protocol for at least four to six weeks before assessing impact. Short testing windows introduce too much noise from external variables like stress, travel, or illness.
Pro Tip: Do not try to personalise everything simultaneously. Optimise sleep first. Almost every other performance variable, from cognitive function to recovery to hormonal balance, improves when sleep quality is genuinely addressed. Use it as your anchor metric.
For further reading on how this translates into practice, explore AI-based wellness strategies and the AI health trends shaping the field in 2026.
Testing, validating, and refining your personalised approach
Applying a personalised protocol without structured validation is like navigating without a map. You might be moving, but you cannot know if you are heading in the right direction.
Key metrics to monitor
- Subjective energy and cognitive function measured by daily mood and focus ratings (simple 1-10 scales work well when applied consistently).
- Sleep quality tracked through sleep efficiency percentage, deep sleep duration, and REM proportion.
- Performance markers such as training output, HRV trends, and recovery time between sessions.
- Biomarker shifts at eight to twelve week intervals, comparing against your personal baseline rather than population reference ranges.
Digital twins and multi-omics validation
Precision medicine integrates multi-omics, combining genomics, proteomics, imaging, and electronic health records to build a layered understanding of your biology. Digital twin technology takes this further by creating a computational model of your physiology that allows clinicians and analysts to simulate interventions before you implement them. Want to know how adding 10g of creatine daily might interact with your current kidney function and methylation patterns? A digital twin can model that scenario with a level of specificity that no population trial can offer.
“Precision medicine integrates multi-omics (genomics, proteomics), imaging, and EHR; digital twins simulate interventions before implementation; clinician oversight remains essential for safety.”
Avoiding the key pitfalls
Overfitting is the most common analytical mistake in N=1 health work. It occurs when your model fits your historical data so precisely that it fails to generalise to new data, producing recommendations that seem logical but do not hold up in practice. Confirmation bias is equally dangerous: you will naturally gravitate toward data that supports what you already believe about your health. A structured validation period with pre-specified success criteria removes this subjective distortion.
Never sideline clinical oversight. For safe and effective long-term personalisation, regular professional review of your health analytics for performance and ongoing precision health strategies is non-negotiable.
A fresh perspective: what most personalisation advice gets wrong
Here is the uncomfortable reality: most personalisation content focuses almost entirely on which tools or algorithms to use, while completely ignoring the conditions that make those tools trustworthy or dangerous.
The biggest mistake we see is people adopting AI-driven health recommendations without any structured human oversight in the loop. Machine learning models are extraordinarily good at finding patterns. They are not good at distinguishing between a pattern that is genuinely causal, a pattern that is coincidental, and a pattern that reflects data bias. Without clinical interpretation, you can follow a recommendation that looks compelling on a dashboard and is actively working against your physiology in ways you cannot detect until something goes wrong.
The second mistake is treating privacy as optional. Local LLMs, federated learning, and clear data ownership are not just technical preferences. They are preconditions for long-term trust in your personalisation system. If your most sensitive biological data sits on a third-party cloud server with opaque data usage policies, your ability to make fully autonomous decisions about your health is compromised from the outset.
The third mistake is skipping validation. Personalisation without structured testing produces what we call the optimisation illusion: you feel like you are making progress because you are doing more, tracking more, and trying more. But without pre-specified success criteria and honest outcome assessment, you are likely cycling through interventions without accumulating genuine physiological improvement.
The most effective personalisation we have seen unfolds slowly, with one variable changed at a time, measured rigorously, validated over at least four to six weeks, and reviewed by a clinician before the next layer of complexity is added. It is far less exciting than the five-biohack transformation content that dominates wellness media. It also actually works. For a practical starting point on making this process rigorous, revisit the power of analysing health data with structured intent.
Next steps: unlock your personalised health optimisation
If you have read this far, you already understand that meaningful personalisation requires deeper data than most people collect. Generic blood panels and consumer wearables capture the surface. Genuine physiological insight requires functional testing and expert analysis calibrated to your individual profile.
At AI Healthician, we combine advanced diagnostics with evidence-informed strategy to build protocols that reflect your actual biology, not population averages. Our DNA health testing service provides genomic insights that inform long-term performance and risk management. For metabolic precision, the metabolic test with 3D body scan delivers a granular picture of how your body actually uses energy. If you want to start with metabolic baseline, the resting metabolic rate test is a practical first step. Each test feeds directly into a personalised protocol designed to generate measurable, sustained improvements.
Frequently asked questions
Can health data personalisation improve my energy and performance?
Yes. Tailored data analysis uncovers the specific physiological factors undermining your energy and performance, enabling targeted interventions that generic advice simply cannot provide.
Which health metrics should I track for optimal personalisation?
Prioritise biometrics such as heart rate and sleep, alongside activity levels, nutrition quality, genomics, and medication and supplement responses for the most clinically useful picture.
How can I ensure the privacy of my health data?
Store sensitive biological data locally wherever possible, use local AI tools, and apply federated learning approaches that keep your data off third-party cloud servers.
Are AI methods reliable for personalising health data?
AI methods can be highly effective when validated against real-world outcomes. However, LLMs have known limitations in medical validation, and clinician oversight is essential for safety and accuracy.
Do I still need to consult healthcare professionals when personalising my health data?
Yes. Regular clinical review ensures your protocols are physiologically safe and that complex biomarker interactions are interpreted correctly over the long term.
Recommended
- Real benefits of health data tracking: 5 key insights – Aihealthician
- Data-Driven Wellness: Transforming Precision Health Outcomes – Aihealthician
- AI in health: personalised wellness strategies for 2026 – Aihealthician
- AI health trends 2026: 18% better sleep, real results – Aihealthician
- Personalized Care in Wellness: Transforming Health Outcomes
- Personalized medicine explained: Your path to optimized health




